
The slides

Just like any system engineer I like best practices. In the context of our subject, this one is probably the source of all evil. Although the blurred out documentation as a whole is correct, it seems to leave much to the imagination of its readers. This best practice is often reduced to:
"Each container should have only one process"
Before we apply this blindly, we should consider the possible implications this rule could have.
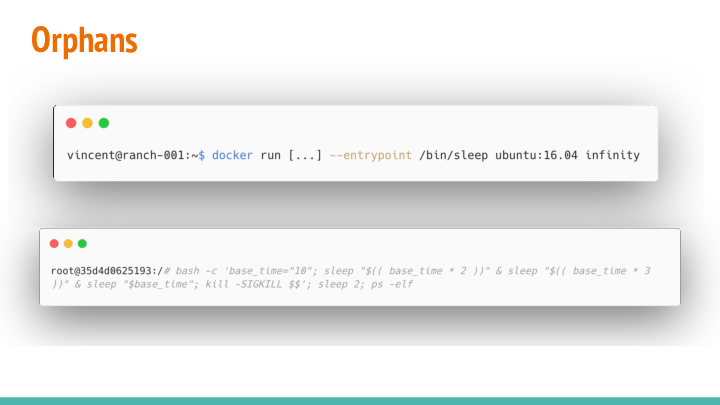
Let’s run a simple application as our container’s entry point: (first window in the image)
docker run --rm -it --entrypoint /bin/sleep ubuntu:16.04 infinity
sleep is a very simple binary that does nothing but what it’s supposed to do: sleep until the specified amount of time has passed; In this case: Forever.
In the second window of the image you see a bash script that creates 2 forks of "sleeper processes" (20s and 30s) in the same container; After forking, it sleeps 10s and kills itself:
bash -c ' \
base_time="10"; \
sleep "$(( base_time * 2 ))" & \
\
sleep "$(( base_time * 3 ))" & \
\
sleep "$base_time"; \
kill -SIGKILL $$ \
'
sleep 2
ps -elf
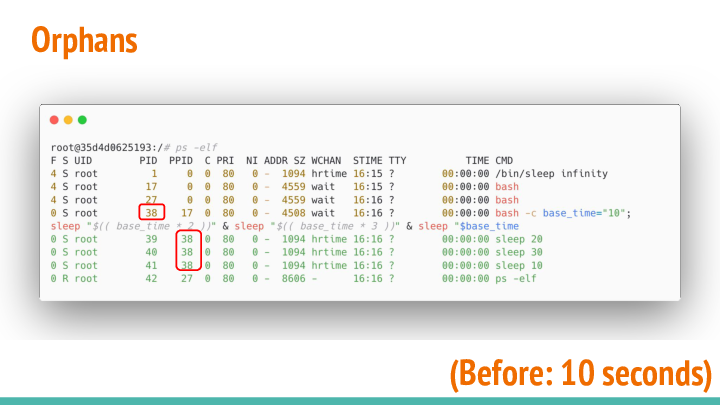
When the script is running, before the initial 10 seconds have passed. We can see what the processes are doing. The forked processes are running as expected. Sleep 20 and 30 are our forks, the parent being the script we invoked earlier.
When we wait until the 10s grace time has passed, we'll notice a change...
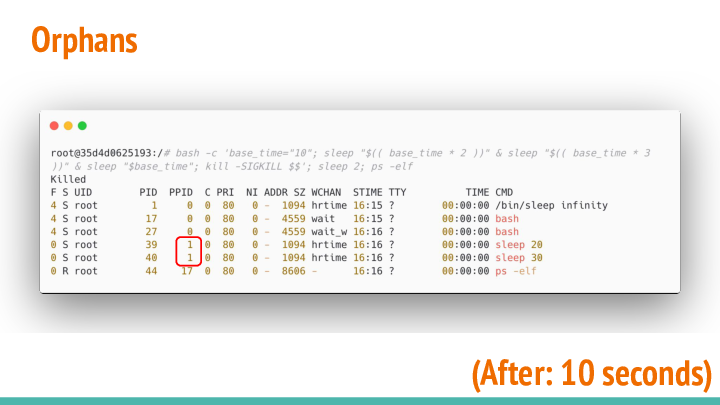
Our script got killed, but its forked processes haven’t finished yet. As their assigned parent process no longer exists, the kernel assigns process with ID 1 as its new parent.
The kernel is assuming that this process is capable of performing the required tasks to complete the lifecycle of its new children.
Now when these children finish executing we’ll notice another change in status...
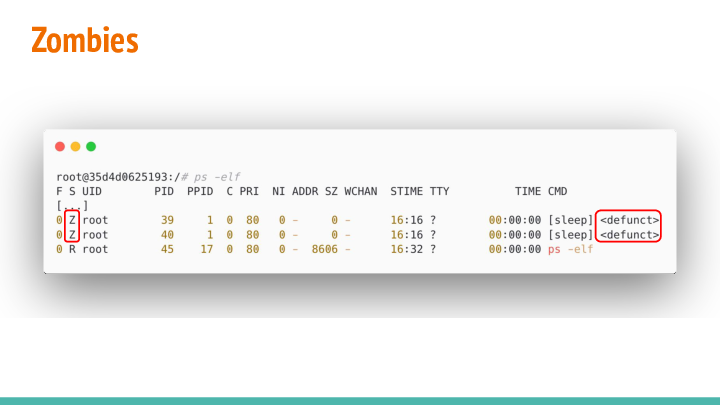
They will have been marked as “zombies”:
In the wild, there’s a lot of explanations given to zombie processes, but it’s a very specific state in the kernel world:
"A child that’s terminated, but has not been waited for yet"
The kernel keeps some metadata about a process inside the process table and keeps it there until one of the waitpid()-family system calls has gathered the process’s information.
This could be an issue because many libraries and applications make the same and similar assumptions. For example Nginx, passenger and many more…
Also...
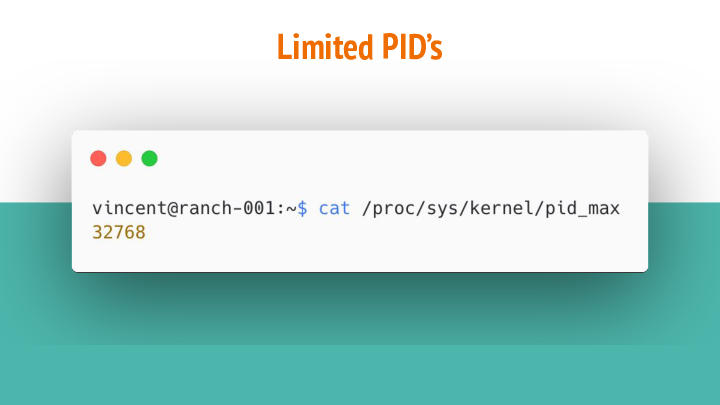
Each PID uses up a system resource. Some people might exclaim that it uses up rogue CPU and memory. While I don’t believe that’s the case, it does use op a limited resource: Entries in the kernel’s process table.
Once there’s no more available PID’s, no new processes can be added. Imagine trying to debug without spawning a new process.
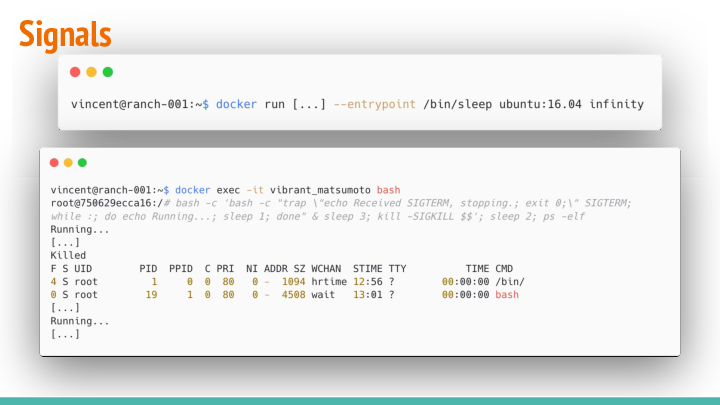
Another closely related issue is signaling.
docker run --rm -it --entrypoint /bin/sleep ubuntu:16.04 infinity
Let’s start another sleeper container, and add a similar script to its processes. The same forking process technique is used, but this time the subprocess tells us it’s running every second and catches SIGTERM signals it receives (prints out it received that), and exits when it does before stopping.
bash -c ' \
bash -c "
trap \"echo Received SIGTERM, stopping.; \
exit 0;\" SIGTERM; \
while :; do \
echo Running...; \
sleep 1; \
done;" & \
sleep 3;
kill -SIGKILL $$ \
'
sleep 2
ps -elf
In the example, we see the trapper-script has been adopted by process ID 1 (sleep)... Let’s see what happens when we ask docker to stop this container.
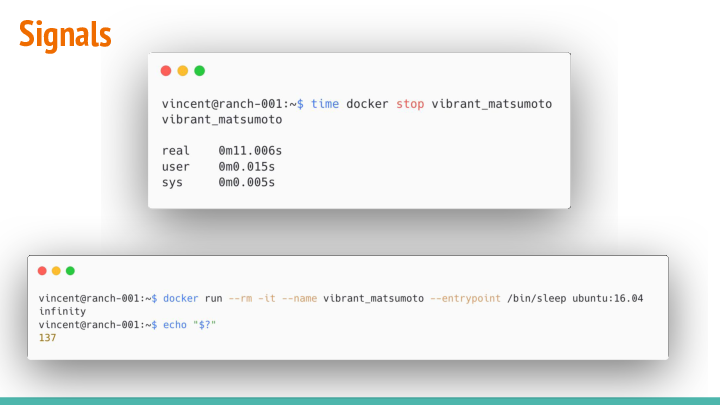
Immediately the stop command’s execution time shows us something is off: It takes longer than the default timeout time. By default 10 seconds after it has sent the SIGTERM, the docker daemon kills the process.
If we double-check this behavior at the docker run command’s exit code, we can confirm that this is what happened:
- It has exit code
137, a convention for expressing error codes in chroot-environments. - The convention is to use
128 + ;<actual exit code;>to emphasize chroot. - This exit code is equal to
137 - 128 = 9->KILLED. - When we’d look at the output of our command that catches the
SIGTERMsignals, we also notice that it hasn’t picked this up.
To put it simply: The process with ID 1 within the container did receive the exit code, but did not:
- Pass it on its children
- Wait for the children to gracefully stop
- Handle
waitpid()-style operations - Only then exit itself
This is a dangerous situation. It could mean data-loss, unexpected service interruption, ...

I’ve discussed these two issues because they are fundamental responsibilities in any Unix system. Luckily it’s easy to fix these issues:
- We can use an init system. I would recommend using a simplified version and not run a full-blown init system from any distribution in your container.
- Docker even has added an
--initparameter you can pass. But I’d personally rather package properly then resort to that. - Another option is to make use of the
PID namespace sharingfunctionality in containers. It sort of comes down to the same concept as having an init system. Kubernetes handles this using this method (using:kubernetes/pausecontainer).
There’s probably an endless stream of possibilities for solving this issue.
Let us know what you think